网站域名服务器查询武汉seo推广
1、蒸馏温度T
正常的模型学习到的就是在正确的类别上得到最大的概率,但是不正确的分类上也会得到一些概率尽管有时这些概率很小,但是在这些不正确的分类中,有一些分类的可能性仍然是其他类别的很多倍。但是对这些非正确类别的预测概率也能反应模型的泛化能力,例如,一辆宝马车的图片,只有很小的概率被误识别成垃圾车,但是被识别成垃圾车的概率还是比错误识别成胡萝卜的概率高很多倍。(例如一个车,猫,狗3分类的模型识别一张猫的图片,最后结果是:(cat,99%) ; (dog,0.95%);(car,0.05%)错误类别 dog 上的概率仍是错误类别 car 的概率的19倍 )
知识蒸馏
这里一个可行的办法是使用大模型生成的模型类别概率作为“soft targets”(使用蒸馏算法以后的概率,相对应的 head targets 就是正常的原始训练数据集)来训练小模型,由于 soft targets 包含了更多的信息熵,所以每个训练样本都提供给小模型更多的信息用来学习,这样小模型就只需要用更少的样本,及更高的学习率去训练了。
仍然是上面的错误分类概率的例子,在 MNIST 数据集上训练的一个大模型基本都能达到 99 % 以上的准确率,假如现在有一个数字 2 的图片输入到大模型中分类,在得到的结果是数字 3 的概率为 10e-6, 是数字 7 的概率为 10e-9,这就表示了相比于 7 ,3更接近于 2,这从侧面也可以表现数据之间的相关性,但是在迁移阶段,这样的概率在交叉熵损失函数(cross-entropy loss function)只有很小的影响,因为它们的概率都基本为0。 所以这里,本文提出了 “distillation” 的概念, 来软化上述的结果。
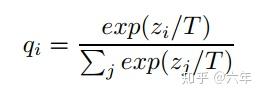
上面的公式就是蒸馏后的 softmax,其中 T 代表 temperature, 蒸馏的温度。那么 T 有什么作用呢?
假设现在有一个数组 x=[2,7,10] ,当T = 1,即为正常的 Softmax函数 输入上式中可得:
T = 1 ——> y = [0.00032,0.04741,0.95227]可以理解为上述的一个车,猫,狗3分类网络,输入一张猫的图片,预测为汽车的概率为0.00032, 预测为狗的概率为 0.04741, 预测为猫的概率为 0.95227。
下面再看一下改变 T 的值概率的输出:
T = 5 ——> y = [0.11532, 0.31348, 0.5712] T = 10 ——> y = [0.20516, 0.33825, 0.45659] T = 20 ——> y = [0.26484, 0.34006, 0.3951]
下面是在(-10,10)之间随机取多个点然后在 不同的 T 值下绘制的图像。
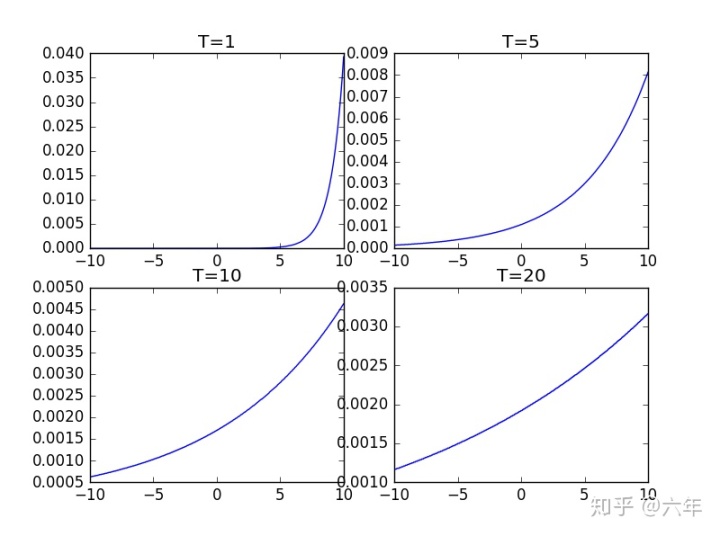
可以看到当 T = 1 是就是常规的 Softmax,而升温T,对softmax进行蒸馏,函数的图像会变得越来越平滑,这也是文中提高的 soft targets 的 soft 一词来源吧。
假设你是每次都是进行负重登山,虽然过程很辛苦,但是当有一天你取下负重,正常的登山的时候,你就会变得非常轻松,可以比别人登得高登得远。我们知道对于一个复杂网络来说往往能够得到很好的分类效果,错误的概率比正确的概率会小很多很多,但是对于一个小网络来说它是无法学成这个效果的。我们为了去帮助小网络进行学习,就在小网络的softmax加一个T参数,加上这个T参数以后错误分类再经过softmax以后输出会变大,同样的正确分类会变小。这就人为的加大了训练的难度,一旦将T重新设置为1,分类结果会非常的接近于大网络的分类效果。
最后将小模型在 soft targets 上训练得到的交叉熵损失函数,加上在真实带标签数据(hard targets)上训练得到的交叉熵损失函数乘以 1/T^2 加在一起作为最后总的损失函数。这里hard targets 上面乘以一个系数是因为 soft targets 生成过程中蒸馏后的 softmax 求导会有一个 1/T^2 的系数,为了保持两个 Loss 所产生的影响接近一样(各 50%)。
训练过程
假设这里选取的 T = 10;
Teacher 模型:
( a ) Softmax(T=10)的输出,生成“Soft targets”
Student 模型:
( a ) 对 Softmax(T = 10)的输出与Teacher 模型的Softmax(T = 10)的输出求 Loss1
( b ) 对 Softmax(T = 1)的输出与原始label 求 Loss2
( c ) Loss = Loss1 + (1/T^2)Loss2
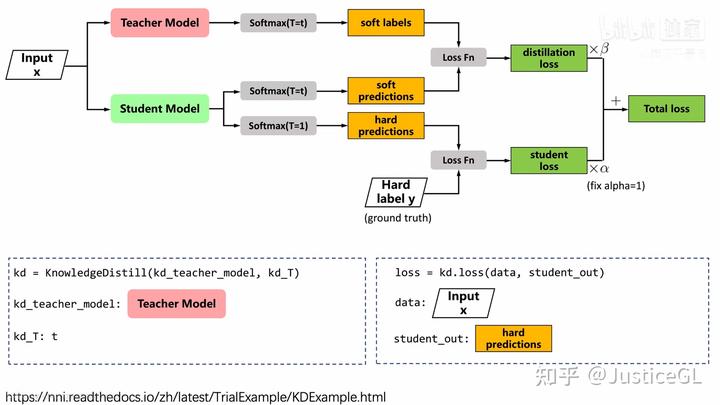
使用soft target会增加信息量,熵高
发现:T参数越大,soft target的分布越均匀。因此,我们可以:
- 首先用较大的T值来训练模型,这时候复杂的神经网络能够产生更均匀分布(更容易让小网络学习)的soft target;
- 之后小规模的神经网络用相同的T值来学习由大规模神经网络产生的soft target,接近这个soft target从而学习到数据的结构分布特征;
- 最后在实际应用中,将T值恢复到1,让类别概率偏向正确类别。
在大数据集上训练专家模型
Training ensembles of specialists on very big datasets
可以用无限大的数据集来使用教师网络训练学生网络
- 当数据集非常巨大以及模型非常复杂时,训练多个模型所需要的资源是难以想象的,因此作者提出了一种新的集成模型(ensemble)方法:
- 一个generalist model:使用全部数据训练。
- 多个specialist model(专家模型):对某些容易混淆的类别进行训练。
- specialist model的训练集中,一半是由训练集中包含某些特定类别的子集(special subset)组成,剩下一半是从剩余数据集中随机选取的。
- 这个ensemble的方法中,只有generalist model是使用完整数据集训练的,时间较长,而剩余的所有specialist model由于训练数据相对较少,且相互独立,可以并行训练,因此训练模型的总时间可以节约很多。
- specialist model由于只使用特定类别的数据进行训练,因此模型对别的类别的判断能力几乎为0,导致非常容易过拟合。
- 解决办法:当 specialist model 通过 hard targets 训练完成后,再使用由 generalist model 生成的 soft targets 进行微调。这样做是因为 soft targets 保留了一些对于其他类别数据的信息,因此模型可以在原来基础上学到更多知识,有效避免了过拟合。
实现流程:

此部分很有意思,但是不知道具体细节,需要再去看论文。